

Sector • Ciberseguridad / Data Science
Análisis y predicción del coste de incidentes de seguridad mediante regresión lineal simple
Proyecto educativo y de prototipo que demuestra cómo usar regresión lineal simple para estimar el coste económico de un incidente de seguridad en función del número de equipos afectados. Dataset sintético (generado aleatoriamente) y flujo completo: generación de datos, visualización, ajuste de modelo y predicción.
Descripción
Este ejercicio implementa un flujo básico de Machine Learning en Google Colab para estimar el coste (económico) asociado a un incidente de seguridad en función del número de equipos afectados. El objetivo es ilustrar conceptos clave de regresión lineal, visualización y uso de librerías estándar (numpy, pandas, scikit-learn) en un caso de ciberseguridad.
Desafío
Demostrar cómo, partiendo de datos (en este caso sintéticos), podemos construir un modelo simple capaz de
relacionar una variable predictora (equipos afectados) con una respuesta numérica (coste del incidente).
Solución
Generación de un dataset sintético, escalado y limpieza básica; visualización exploratoria; entrenamiento de una
regresión lineal con scikit-learn y uso del modelo para realizar predicciones de ejemplo (p. ej. coste estimado para 1300 equipos afectados).
Proceso / Pasos
4 pasos
Step 1 — Generación del dataset
Se genera un dataset sintético con numpy: variable predictora (n.º de equipos afectados) y variable objetivo (coste) con ruido añadido para simular variabilidad real.
Step 2 — Visualización y preprocesado
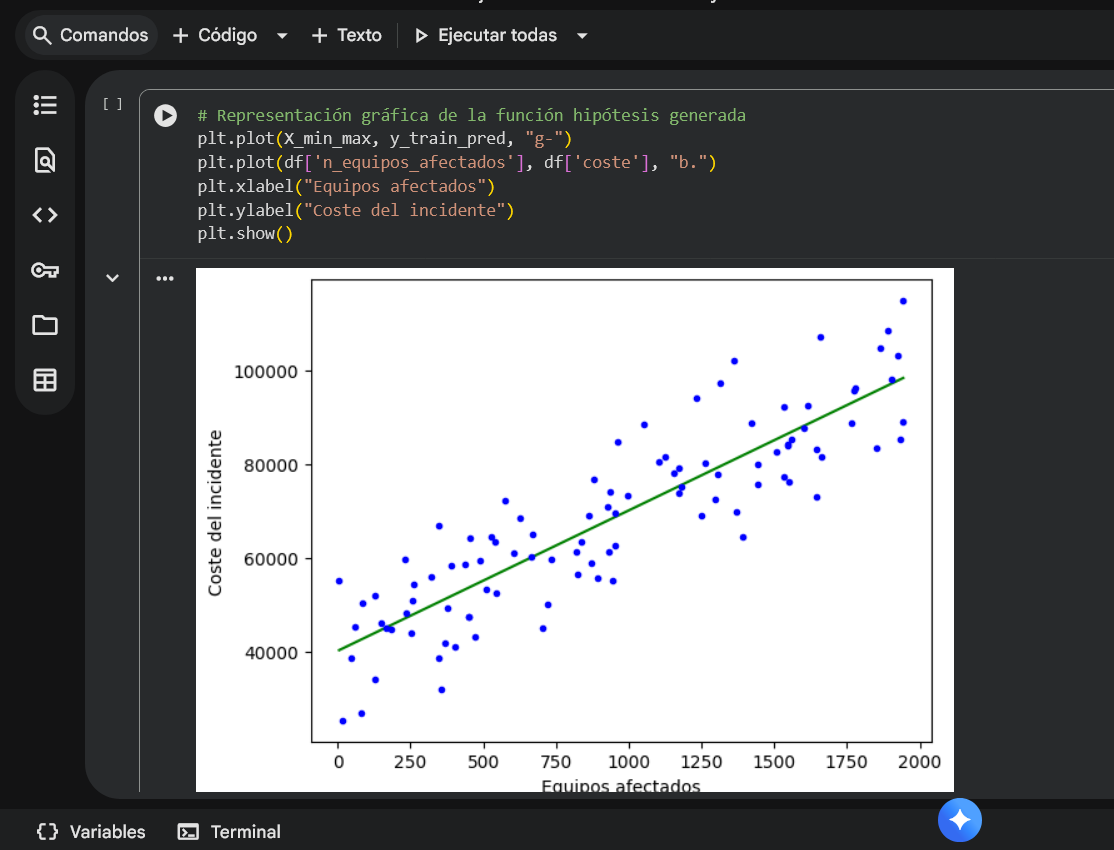
Se visualiza la relación con matplotlib, se normalizan/escalan campos si es necesario y se transforma el dataset a DataFrame con pandas para facilitar el análisis.
Step 3 — Entrenamiento del modelo
Se ajusta una regresión lineal simple con scikit-learn (LinearRegression). Se obtienen los parámetros (intercept y coeficiente) y se grafica la recta de ajuste sobre los datos.
Step 4 — Predicción de ejemplo y visualización
Se realizan predicciones para nuevos valores (ej. 1300 equipos afectados) y se muestra en la gráfica la predicción como punto destacado. Al ser dataset sintético, los resultados son ilustrativos.
Resultados (ejemplo)
- Flujo completo reproducible en Google Colab: generación de datos → visualización → entrenamiento → predicción.
- Modelo interpretable (regresión lineal), útil para ejercicios de prototipado y validación de hipótesis en ciberseguridad.
- El notebook sirve como material didáctico para entender cómo relacionar métricas operativas (equipos afectados) con costes estimados.
Repositorio (si aplica)
Contactar